Khoảng tin cậy
Khoảng tin cậy là gì:
Đây là ước tính của một phạm vi được sử dụng trong các số liệu thống kê, trong đó có chứa một tham số dân số. Thông số dân số chưa biết này được tìm thấy thông qua một mô hình mẫu được tính toán từ dữ liệu thu thập được .
Ví dụ: trung bình của một mẫu được thu thập x̅ có thể hoặc không khớp với trung bình dân số thực. Đối với điều này, có thể xem xét một phạm vi mẫu có nghĩa là nơi có thể chứa dân số này. Khoảng thời gian này càng dài, khả năng xảy ra điều này càng lớn.
Khoảng tin cậy được biểu thị bằng phần trăm, được biểu thị bằng mức độ tin cậy, với 90%, 95% và 99% được biểu thị nhiều nhất. Trong hình ảnh bên dưới, ví dụ, chúng ta có khoảng tin cậy 90% giữa giới hạn trên và dưới của nó (a và -a ).
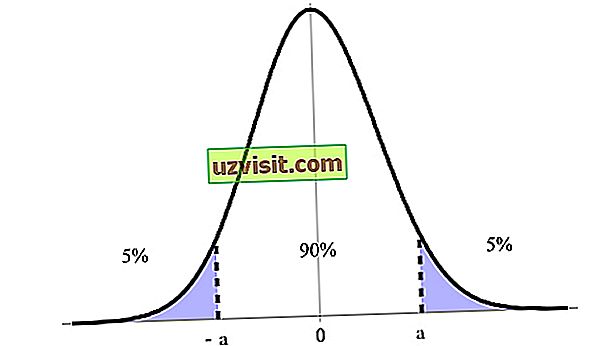
Khoảng tin cậy là một trong những khái niệm quan trọng nhất trong kiểm tra giả thuyết trong thống kê, bởi vì nó được sử dụng như một thước đo về độ không chắc chắn. Thuật ngữ này được giới thiệu bởi nhà toán học và thống kê người Ba Lan Jerzy Neyman vào năm 1937.
Sự liên quan của khoảng tin cậy là gì?
Khoảng tin cậy là quan trọng để chỉ ra biên độ không chắc chắn (hoặc không chính xác) so với tính toán được thực hiện. Tính toán này sử dụng mẫu nghiên cứu để ước tính kích thước thực tế của kết quả trong quần thể nguồn.
Việc tính toán khoảng tin cậy là một chiến lược xem xét lấy mẫu lỗi. Quy mô của kết quả học tập và khoảng tin cậy của bạn đặc trưng cho các giá trị giả định cho dân số ban đầu.
Khoảng tin cậy càng hẹp, xác suất tỷ lệ phần trăm dân số nghiên cứu đại diện cho số lượng thực sự của dân số nguồn càng lớn, mang lại sự chắc chắn hơn về kết quả của đối tượng nghiên cứu.
Làm thế nào để giải thích một khoảng tin cậy?
Giải thích chính xác về khoảng tin cậy có lẽ là khía cạnh thách thức nhất của khái niệm thống kê này. Một ví dụ về cách giải thích phổ biến nhất của khái niệm này là như sau:
Có xác suất 95% rằng, trong tương lai, giá trị thực của tham số dân số (ví dụ: trung bình) nằm trong phạm vi X (giới hạn dưới) và Y (giới hạn trên).
Do đó, khoảng tin cậy được diễn giải như sau: tin tưởng 95% rằng khoảng giữa X (giới hạn dưới) và Y (giới hạn trên) chứa giá trị thực của tham số dân số.
Sẽ là hoàn toàn không chính xác khi tuyên bố rằng: có xác suất 95% rằng khoảng giữa X (giới hạn dưới) và Y (giới hạn trên) chứa giá trị thực của tham số dân số.
Tuyên bố trên là quan niệm sai lầm phổ biến nhất về khoảng tin cậy. Sau khi phạm vi thống kê được tính toán, nó chỉ có thể chứa tham số dân số hoặc không.
Tuy nhiên, các khoảng có thể khác nhau giữa các mẫu, trong khi tham số dân số thực là như nhau bất kể mẫu.
Do đó, tuyên bố độ tin cậy khoảng tin cậy chỉ có thể được thực hiện trong trường hợp khoảng tin cậy được tính toán lại cho số lượng mẫu.
Các bước tính toán khoảng tin cậy
Phạm vi được tính bằng các bước sau:
- Thu thập dữ liệu mẫu: n ;
- Tính trung bình mẫu x̅;
- Xác định xem độ lệch chuẩn dân số ( σ ) được biết hay chưa biết;
- Nếu độ lệch chuẩn dân số được biết đến, điểm z có thể được sử dụng cho mức độ tin cậy tương ứng;
- Nếu độ lệch chuẩn dân số là không xác định, chúng ta có thể sử dụng thống kê t cho mức độ tin cậy tương ứng;
- Do đó, giới hạn dưới và trên của khoảng tin cậy được tìm thấy bằng các công thức sau:
a) Độ lệch chuẩn của một dân số đã biết :
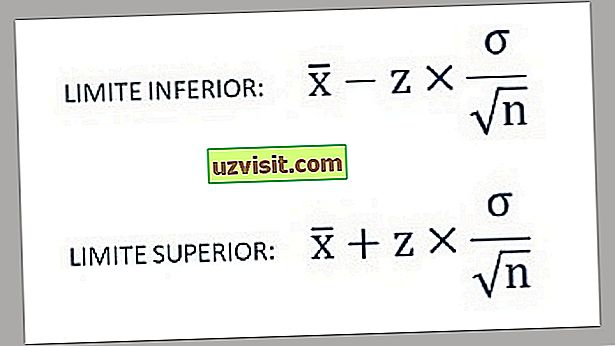
Công thức tính độ lệch chuẩn của một dân số đã biết.
b) Độ lệch chuẩn của một dân số chưa biết :

Công thức tính độ lệch chuẩn của một quần thể chưa biết.
Ví dụ thực tế về khoảng tin cậy
Một nghiên cứu lâm sàng đã đánh giá mối liên quan giữa sự hiện diện của bệnh hen suyễn và nguy cơ mắc chứng ngưng thở khi ngủ tắc nghẽn ở người lớn.
Một số người trưởng thành được tuyển chọn ngẫu nhiên từ một danh sách các quan chức nhà nước sẽ được theo dõi trong bốn năm.
Những người tham gia mắc bệnh hen suyễn, khi so sánh với những người không mắc bệnh, có nguy cơ mắc chứng ngưng thở cao hơn trong bốn năm.
Khi tiến hành nghiên cứu lâm sàng như ví dụ này, một tập hợp con của dân số quan tâm thường được tuyển dụng để tăng hiệu quả nghiên cứu (ít chi phí và ít thời gian hơn).
Nhóm cá nhân này, dân số được nghiên cứu, bao gồm những người đáp ứng các tiêu chí thu nhận và đồng ý tham gia nghiên cứu, như trong hình dưới đây.

Sau đó, nghiên cứu được hoàn thành và kích thước hiệu ứng (ví dụ: chênh lệch trung bình hoặc rủi ro tương đối ) được tính toán để trả lời câu hỏi nghiên cứu.
Quá trình này, được gọi là suy luận, liên quan đến việc sử dụng dữ liệu được thu thập từ dân số nghiên cứu để ước tính quy mô của hiệu ứng thực tế đối với dân số quan tâm, nghĩa là dân số nguồn gốc.
Trong ví dụ đưa ra, các nhà nghiên cứu đã tuyển chọn một mẫu ngẫu nhiên các nhân viên nhà nước (dân số nguồn) đủ điều kiện và đồng ý tham gia nghiên cứu (dân số nghiên cứu) và báo cáo rằng hen suyễn làm tăng nguy cơ mắc chứng ngưng thở trong dân số nghiên cứu.
Để tính lỗi lấy mẫu do chỉ tuyển dụng một nhóm nhỏ trong nhóm người quan tâm, họ cũng đã tính khoảng tin cậy 95% (xung quanh ước tính) là 1, 06 - 1, 82, cho thấy xác suất 95 % rằng rủi ro tương đối thực sự trong dân số nguồn sẽ nằm trong khoảng từ 1, 06 đến 1, 82 .
Khoảng tin cậy cho trung bình
Khi một người có thông tin về độ lệch chuẩn của dân số, người ta có thể tính khoảng tin cậy cho mức trung bình hoặc trung bình của dân số đó.
Khi một đặc điểm thống kê đang được đo lường (như thu nhập, IQ, giá cả, chiều cao, số lượng hoặc cân nặng) là bằng số, trong hầu hết các trường hợp, người ta ước tính rằng giá trị trung bình của dân số được tìm thấy.
Vì vậy, chúng tôi cố gắng tìm trung bình dân số ( μ ) bằng cách sử dụng trung bình mẫu ( x̅ ), với biên sai số. Kết quả của phép tính này được gọi là khoảng tin cậy cho trung bình dân số .
Khi độ lệch chuẩn dân số được biết đến, công thức cho khoảng tin cậy (CI) cho trung bình dân số là:

Ở đâu:
- x̅ là giá trị trung bình mẫu;
- là độ lệch chuẩn dân số;
- n là cỡ mẫu;
- * Biểu thị giá trị phù hợp của phân phối chuẩn thông thường cho mức độ tin cậy mong muốn của bạn.
Sau đây là các giá trị cho các mức độ tin cậy khác nhau ( * ):
| Mức độ tin cậy | Giá trị của Z * - |
|---|---|
| 80% | 1, 28 |
| 90% | 1.645 (thông thường) |
| 95% | 1, 96 |
| 98% | 2, 33 |
| 99% | 2, 58 |
Bảng trên cho thấy giá trị z * cho các mức độ tin cậy được cung cấp. Lưu ý rằng các giá trị này được lấy từ phân phối chuẩn thông thường (Z-).
Vùng giữa mỗi giá trị z * và âm của giá trị này là tỷ lệ phần trăm tin cậy (gần đúng). Ví dụ: khu vực giữa z * = 1, 28 và z = -1, 28 xấp xỉ 0, 80. Do đó, bảng này cũng có thể được mở rộng sang tỷ lệ tin cậy khác. Bảng này chỉ hiển thị tỷ lệ phần trăm được sử dụng phổ biến nhất của niềm tin.
Xem thêm ý nghĩa của giả thuyết.